 Skip to content
Skip to content

“Custom AI” is one of the most overused phrases in the market today. Everybody claims they’re doing it, every demo promises and demonstrates it, and every pitch deck highlights it.
Yet, when we speak to CIOs, CPOs, and Heads of Digital in regulated enterprises, there is consistent confusion about what “custom” actually means in practice.
- Is it prompt tuning?
- Is it feeding internal data into a model?
- Is it fine-tuning?
- Is it building a model from scratch?
In many cases, the answer is unclear, because there is a fair amount of misinformation that sellers are capitalizing on, and the market has blurred critical architectural distinctions. However, in reality, regulated environments cannot work with academic definitions and distinctions. It is metrics like reliability, risk, compliance, and long-term ROI, that play the key role here.
So let’s break this down properly and understand what works where.
The Customisation Spectrum
Not all “custom AI” means the same thing. Most offerings sit at very different points on a spectrum. Understanding where a solution sits creates the difference between building infrastructure and buying a feature.
1. Prompt Engineering
What is it?
The base model remains unchanged. Behaviour is influenced only through carefully crafted prompts.
Where does it work best?
- Early experimentation
- Simple content generation
- Low-risk internal workflows
Where should it not be used?
- Complex, multi-step workflows
- Ambiguous user inputs
- Regulated decision journeys
Fundamentally, we must understand that prompts do not change how a model reasons. They only influence how the model responds. As workflows get layered, prompts become longer, harder to maintain, and increasingly unpredictable.
Prompt engineering may be useful, but it is not a foundation.
2. Retrieval-Augmented Generation (RAG)
What is it?
The model fetches relevant information from your documents, policies, or knowledge base before responding.
Where does it work best?
- Policy lookups
- Product information
- Regulatory references
- Internal knowledge assistants
Where should it not be used?
- Risk classification
- Intent interpretation
- Behavioural decisions
While RAG improves factual accuracy, it does not change reasoning behaviour.
A RAG system can tell you what the policy says, but iIt cannot decide how cautiously to behave. In regulated environments, that distinction is critical.
3. Fine-Tuning
What is it?
The base model is fine-tuned on domain data to improve tone, style, and task performance.
Where does it work best?
- Domain-specific language
- Structured tasks
- Narrow classification problems
Where should it not be used?
- High-risk decision workflows
- Multi-stage reasoning
- Complex user journeys
Fine-tuning improves alignment, but it does not redefine the model’s core reasoning logic. It is a step forward, but still constrained by the architecture of a general-purpose model. In regulated systems, while, alignment is necessary, but it is often not sufficient by itself.
4. Domain-Trained Models and Small Language Models (SLMs)
What is it?
Small, specialised models trained specifically for defined workflows, risk profiles, and user contexts.
Where does it work best?
- Lending eligibility
- Claims processing
- KYC validation
- Collections workflows
- Multilingual support journeys
These models are trained on real domain data, actual workflow patterns, real user language and known edge cases and are evaluated against risk scenarios, compliance outcomes and operational behaviours.
This is not about making a model smarter, but making it safer. SLMs are sharpshooters and are designed to do one thing extremely well, consistently, and predictably. In regulated environments, predictability is trust and key for performance.
5. System-Level Design – Where Most “Custom AI” Fails
This is the layer almost everyone ignores.
AI does not operate in isolation. It operates inside systems.
Real customisation lives in:
- orchestration
- guardrails
- staged decision flows
- escalation logic
- validation layers
- human-in-the-loop design
A well-designed system decides:
- when the model should act
- when it should defer
- when it should escalate
- when it should stop
This is not a model problem. This is a system design problem.
Most AI failures in production are not because the model was weak. They are because the system around it was shallow.
Why This Matters in Regulated, Multilingual Environments
In regulated industries, AI is not an assistant. It is part of the decision fabric.
It influences:
- onboarding
- eligibility
- claims outcomes
- collections strategies
- customer servicing
- compliance posture
At this level, behaviour matters more than capability.
Add multilingual reality to this and complexity compounds.
Users do not speak in clean, structured English. They mix languages. They soften phrasing. They imply intent. They avoid directness. They express emotion through regional idiom.
Generic models struggle here. Not because they cannot translate. But because they cannot reliably interpret risk across languages.
This is why domain-trained models combined with strong orchestration outperform general-purpose approaches in real production systems.
Architecture Outline For Serious Systems
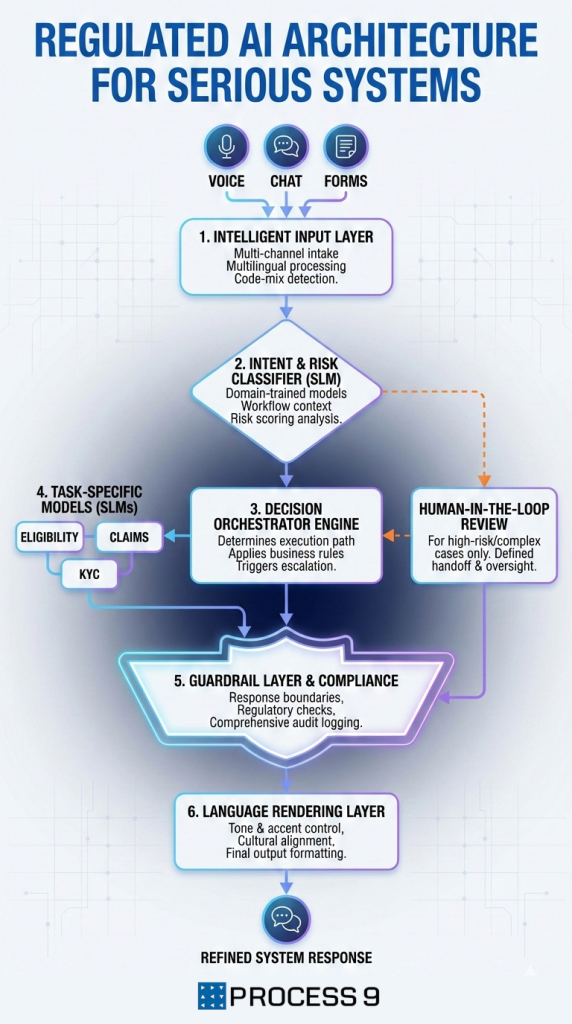
A typical regulated AI architecture looks like this:
- Input Layer
- Voice, chat, forms
- Multilingual handling
- Code-mix detection
- Intent & Risk Classifier (SLM)
- Domain-trained model
- Workflow-aware
- Risk scoring
- Decision Orchestrator
- Determines path
- Applies business rules
- Triggers escalation where needed
- Task-Specific Models
- Eligibility SLM
- Claims SLM
- KYC SLM
- Guardrail Layer
- Response boundaries
- Compliance checks
- Audit logging
- Human-in-the-Loop
- Only where necessary
- Clearly defined handoff
- Language Rendering Layer
- Tone control
- Accent handling
- Cultural alignment
This is not “one model with a big prompt”. This is infrastructure.
The Hidden Cost of Getting This Wrong
When organisations treat “custom AI” lightly, they pay for it later.
They face issues like:
- rising manual intervention
- growing exception handling
- increased audit overhead
- loss of trust from business teams
- AI fatigue across functions
The system technically works. Operationally, it fails. This is how many AI programs get stalled quietly. Not because AI is overhyped, but because the design was shallow.
Our Design Philosophy
At Process9, we design AI the way we design infrastructure.
- Purpose-built
- Workflow-aware
- Risk-aligned
- Multilingual by design
- Governed from day one
We do not believe in building one model to handle everything. We believe in building the right model for the right job. It is slower at the start, but dramatically faster at scale. And it is the only approach that survives real enterprise reality.
A Simple Test for Buyers
If your AI behaves differently only because you changed the prompt, it is not truly custom. If it behaves differently because it was designed differently, then it is. That is the difference between configuration and architecture.
In regulated environments, this difference is everything.





Share: